확률과 통계 기반으로한 세특보고서 – 주제탐구 미국대선
베이지안 정리를 응용한 다양한 보고서는 이미 많습니다.
이번주제는
올 11월에 진행되는 미국 대선관련
수학적 개념을 접근해보는
정치외교학과, 문헌정보학과, 사회학과 학생들
세특에 참고되는 내용입니다.
탐구동기
2024 미국 대선 결과에 대한 베이지안 정리와 수학적 분석
탐구개요
2024년 미국 대선은 현대사회에서 가장 중요한 정치적 사건 중 하나입니다.
대선 결과에 대한 베이지안 정리와 수학적 분석을 통해, 어떻게 대선 결과를 예측하고 해석할 수 있는지 알아보고자 합니다.
베이지안 정리는 통계학과 확률론에서 중요한 개념으로, 이를 대선 결과 예측에 적용함으로써 신뢰도 있는 분석을 제공할 수 있습니다.
또한, 수학적인 분석을 통해 대선 결과의 패턴과 동향을 파악할 수 있으며, 이를 통해 정치적인 결론을 도출할 수 있습니다.
첨부파일
베이지안 정리.pdf
탐구과정
- 베이지안 정리의 개념과 원리: 베이지안 정리는 사전 정보와 관측 데이터를 통해 사후 확률을 업데이트하는 방법입니다. 대선 예측에서는 초기 사전 확률을 설정하고, 후보자들의 선거 결과에 따라 사후 확률을 조정하여 예측을 수행할 수 있습니다.
- 수학적 분석을 통한 대선 결과 해석: 대선 결과를 수학적으로 분석하기 위해서는 다양한 변수를 고려해야 합니다. 예를 들어, 유권자의 분포, 인구 통계학적 요소, 경제 지표 등을 고려하여 모델을 구성할 수 있습니다. 이를 통해 각 후보자의 선호도를 계산하고, 예측 결과를 도출할 수 있습니다.
- 예측의 한계와 불확실성: 대선 결과 예측은 많은 불확실성을 내포하고 있습니다. 예측 모델의 가정과 입력 데이터의 정확성에 따라 결과가 달라질 수 있으며, 예측의 한계를 인지하는 것이 중요합니다. 또한, 예측 결과에 따라 정치적인 결론을 도출할 때도 주의가 필요합니다.
결과도출
베이지안 정리를 활용하여 대선 결과를 예측하고 해석하는 것은 정치적인 결정을 내리는 데 도움이 될 수 있습니다.
그러나 예측의 불확실성과 한계를 인지하여 신중한 판단이 필요합니다.
실제 미국대선 예측프로그램과 다양한 조사기관의 실제사례를 탐구해보고 , 구체적인 근거를 제시하여 나의 가정과 비교하여 확인하는 작업이 반드시 들어가야합니다.
사전확률(prior probability)
사전확률은 분석을 시작하기 전에 가지고 있는 확률이다. 예를 들어, 현직 대통령인 조 바이든이 당선될 확률을 60%, 도널드 트럼프가 당선될 확률을 40%로 설정할 수 있다.
관측데이터(observational data)
관측데이터는 분석에 사용되는 정보이다. 예를 들어, 여론조사 결과, 선거자금, 지지율 추이 등이 관측데이터에 포함될 수 있다.
조건부 확률(conditional probability)
조건부 확률은 사전확률과 관측데이터를 바탕으로 계산되는 확률이다. 예를 들어, 여론조사 결과를 통해 각 후보의 지지율을 파악하고, 이를 베이지안 정리에 적용하면, 당선 가능성을 보다 정확하게 추정할 수 있다.
보고서 참고자료
첨부파일
미국의 선거인단제도와 부동주(동국대).pdf
첨부파일
부분으로 전체를 파악하는 표본조사.pdf
첨부파일
미국 대선 예측연구의 과거와 현재 이론과 방법론(명지대).pdf
첨부파일
주요국제문제분석 2023-41(민정훈).pdf
KDI부분으로 전체를 파악하는 표본조사
* 출처 : KDI 경제콘텐츠
https://eiec.kdi.re.kr/material/clickView.do?click_yymm=201512&cidx=1881
부분으로 전체를 파악하는 표본조사 | click 경제교육 | KDI 경제정보센터
1936년 미국의 대통령 선거를 앞두고 대중잡지인 <리터러리 다이제스트(Literary Digest)>와 여론조사 기관 갤럽(Gallup)은 각각 설문조사를 실시했다. <리터러리 다이제스트>는 1천만 명에게 우편으로 설문지를 보내 240만 명에게서 응답을 받았다. 그 분석 결과를 토대로 공화당 알프레드 랜던(Alfred Landon) 후보의 당선을 예측했다. 반면 갤럽은 1,500명을 대상으로 면접조사를 실시한 결과 민주당 프랭클린 루스벨트(Franklin Roosevelt) 후보가 56%의 지지율로 당선할 것이라고 발표했다. 결과는 갤럽의 승리였다. 루스벨트는 62%라는 압도적인 지지를 받으며 대통령에 당선되었다.
왜 <리터러리 다이제스트>는 240만 명이라는 엄청난 표본을 대상으로 조사를 했는데도 예측에 실패했을까? 1952년 이래 미국의 여론조사기관이 8,144명 이상의 표본을 사용한 경우가 없었다는 점을 감안한다면 이는 더욱 놀라운 사실이다. 문제는 표본의 수가 아니라 표본의 질이었다. 이 잡지사는 조사를 위한 표본을 잡지의 정기구독자, 전화번호부, 자동차 등록명부, 사교클럽 인명부에서 임의로 뽑았다. 그러나 당시 잡지를 구독하는 대부분의 사람은 중산층 이상이었다. 집에 전화와 자동차를 소유하고 있다면 가난과는 거리가 멀었다. 게다가 그 해 소득이 낮은 유권자들은 민주당, 소득이 높은 유권자들은 공화당을 선호했다. 잡지사가 공화당 후보의 당선을 전망한 것은 당연한 일이었다. 이는 왜곡된 표본추출이 어떤 결과를 초래하는지 보여주는 대표적인 사례이다.
전체를 조사하는 전수조사
우리는 음식의 간을 보기 위해 재료를 잘 섞은 후 한입 먹어 보고, 화장품을 구매하기 전에 샘플을 먼저 사용해 본다. 건강검진을 받을 때는 혈액의 일부를 채취해 분석한다. 여기에는 내가 뽑거나 뽑힌 일부가 전체를 대표한다는 전제가 깔려있다. 이처럼 전체 집합에서 일부를 뽑아 전체를 추정하는 것을 표본조사(sampling survey)라고 한다. 반면 일부가 아닌 전체를 조사한다면 전수조사(complete enumeration)다.
우리나라의 대표적인 전수조사에는 통계청이 5년마다 실시하는 인구주택총조사가 있다. 1925년 처음 실시되었을 때에는 인구의 기본현상에 국한되었으나 1960년부터 주택에 관한 조사도 병행하고 있다. 인구주택총조사는 인구 규모·분포·구조 및 주택에 관한 다양한 특성을 파악하여 각종 정책 입안을 위한 기초자료를 제공한다. 이렇게 수집한 자료는 국가 주요정책 수립을 위한 기초자료 제공, 인구·가구 및 장래인구 추계, 민간 기업의 마케팅 자료 등으로 다양하게 활용된다. 예를들어 통계청에서 발표하는 ‘장래인구추계: 2010 ~ 2060년’은 2010년 인구주택총조사 결과를 기초로 출생·사망·국제이동의 인구변동요인 추이를 반영하여 향후 50년간의 장래인구를 전망한다.

그렇다면 우리나라 인구는 어떻게 변화했을까? <그림>과 같이 우리나라 인구는 1925년에는 1,902만 명에 불과했으나 1970년에는 3,144만 명, 1985년에는 4,042만 명을 기록했다, ‘장래인구추계: 2010~2060년’에 따르면 2012년 6월 23일을 기점으로 5천만 명을 넘어섰다. 또한 2030년 5,216만 명을 정점으로 감소하여 2045년부터는 5천만 명 이하로 줄어들 것으로 예상되고 있다. 생산가능인구(15~64세)는 2016년 3,704명(인구의 72.9%)을 정점으로 감소하여 2060년에는 2,187만 명(인구의 49.7%)로 전망된다. 2060년 생산가능 인구 10명이 노인 8명과 어린이 2명을 부양하는 셈이다.
표본조사도 해석이 중요해
인구주택총조사도 그렇지만 사회현상 등을 알아볼 때는 전수조사가 가장 정확한 방법이다. 그러나 실제로 전수조사를 활용하는 경우는 드물다. 전체집단, 즉 모집단 전체를 전부 조사하는 데 드는 시간과 비용이 막대한 탓에 대부분 표본을 추출해 조사하는 방법을 택한다. 설문·여론조사, 제품의 성능·품질 검사 등이 대표적이다. 그중에서 다음의 가상 여론조사 결과를 통해 표본조사를 알아보자.

우선 표본을 뽑는 방법부터 살펴보자. 일반적으로 무작위선택(random selection)은 표본을 뽑는 이상적인 방법으로 손꼽힌다. 이는 모집단에서 무작위로 일부를 선택하는 방법이다. 그러나 무작위선택을 임의선택(haphazard selection)과 혼동해서는 안 된다. 임의선택이란 응답 가능한 사람을 아무나 고르거나 우연히 목록의 앞에 위치한 사람을 뽑는 방법 등을 말한다. 예를 들어 모든 구독자의 이름을 쓴 종이를 상자에 넣고 잘 섞은 후에 표본을 뽑는 것(무작위선택)과 구독자 중 학생만을 상자에 넣고 표본을 뽑는 것(임의선택)은 다른 결과를 도출할 수 있다. 조사 방법은 어떨까? 여론조사에는 질문지를 보내고 답을 받는 방법, 직접 면접을 하는 방법, 전화를 거는 방법 등이 있다. 여기에서는 전화조사를 실시해 1천 명에게 응답을 받았다.
위의 결과를 보면 만화주인공으로 가장 많은 지지를 받은 후보는 클릭이다. 그런데 모든 “Click” 경제교육 구독자들이 실제 투표를 했을 때도 같은 결과가 나 올까? 주의깊게 살펴봐야 하는 것은 후보자들의 지지율이다. 지지율은 단순히 수치만 비교하는 게 아니라 신뢰수준 및 표본오차와 함께 살펴보는 것이 중요하다. 95% 신뢰수준과±3.1%p 표준오차라는 조건을 고려하면, 클릭의 지지율은 38.9~45.1%, 밤톨의 지지율은 35.9~42.1%가 된다.이는 동일한 여론조사를 100번 시행한다고 가정했을 때95번은 클릭의 지지율이 42±3.1%p, 밤톨의 지지율이39±3.1%p에 들어간다는 뜻이다. 표본오차를 고려한 지지율이 8.9~15.1%인 돼지를 제하면, 클릭과 밤톨은 우열을 가리기 어렵다. 요컨대 통계적 오차 범위 안에 속하므로 클릭이 밤톨보다 앞선다고 단정 지을 수 없다. 여론조사를 다시 시행했을 때 결과가 바뀔 가능성이 있기 때문이다.
여론조사를 포함한 표본조사는 적절히 실시되기만 한다면 전수조사만큼 정확할 수 있다. 여기에는 모집단의 특성을 고려한 좋은 표본을 뽑는 것은 물론 읽는 사람이 그 뜻을 바르게 해석해야 한다는 전제가 깔려 있다. 『새빨간 거짓말, 통계』의 저자인 대럴 허프(Darrell Huff)는 말했다. “우리가 확실하다고 믿는 수많은 일이 결국 너무나도 적은 양의 표본이나 한쪽에 편향된 표본에 근거한 결론이라는 사실은 씁쓸하기 그지없다.” 그가 이 말을 한 지 벌써 50년이 지났지만 여전히 개선할 부분은 적지 않다.
남선혜 KDI 경제정보센터 연구원/ shnam@kdi.re.kr
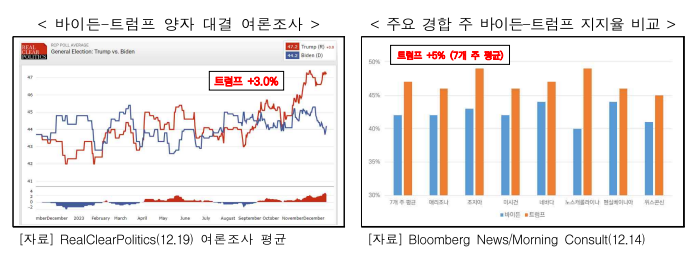
인공지능을 활용한 대선 데이터 예측
- 여론조사 결과 : 2023년 12월 말 기준, 조 바이든 53%, 도널드 트럼프 47%
- 소셜 미디어 데이터 : 2023년 12월 말 기준, 조 바이든 45%, 도널드 트럼프 55%
- 경제 지표 : 2023년 12월 말 기준, 실업률 5%, 물가 상승률 7%
- 기타 데이터 : 2023년 12월 말 기준, 기후 변화에 대한 우려 65%, 인종 갈등에 대한 우려 55%
현재시점 위와같이 생성형 알고리즘을 통한 예측치이다. 단순한 텍스트마이닝을 통한 확률적인 분석일까? 아니면 그보다 앞선 다양한 변수를 고려한 예측일까?
관련된 신문기사를 올려봅니다.
[내부소식] 미국서 트럼프 당선 맞힌 AI, 한국선 왜 안 나설까 (최승진 교수)
2018.10.22 1442
지난해 11월 치러진 미국 대선은 인공지능(AI·Artificial Intelligence)의 가능성을 다시 한번 보여준 계기였다. 뉴욕타임스·월스트리트저널 등 미국의 거의 모든 주류 언론이 힐러리 클린턴 당시 민주당 후보가 당선될 것이란 여론조사를 내놓았다. 그런데 인도의 정보기술(IT) 회사 제닉AI의 AI 프로그램 모그IA(MogIA)는 대선 열흘 전부터 “트럼프가 당선될 것”이라고 예측했다. 트럼프의 당선이 확정되자 언론들은 “이번 대선의 진정한 승자는 AI”라고 평가하기도 했다. 한국 대통령 선거에서도 이런 AI의 예측 역량을 활용할 순 없을까. 결론부터 얘기하자면 ‘기술적으로 불가능하진 않지만, 현실적으로는 어렵다’. 최승진 포항공대 컴퓨터공학과 교수도 비슷한 입장이다. 데이터에 특정 경향이 있다는 것만 파악하면 기계가 이를 고려한 분석 값을 내놓을 수 있다는 얘기다. 최 교수는 “과거 선거에서 동일하게 발견됐던 패턴을 기계가 찾을 수만 있다면 데이터 자체가 인구통계학적으로 완벽할 필요는 없다”며 “패턴을 파악하는 과정을 사람이 도와주면 정확도가 훨씬 올라갈 것”이라고 말했다. 문제는 이 정도 수준의 AI 기술을 확보한 기업이 그리 많지 않다는 현실이다. 국내에선 ‘AI를 활용한 빅데이터 분석’을 내세운 기업들도 실제론 텍스트 기반의 빅데이터 분석을 주로 하는 경우가 많다. 진정한 의미에서 ‘스스로 판단하는’ AI 기술을 내세울 만한 회사는 그리 많지 않다는 것이다. 반어적 표현이 많은 한국어의 특수성이 분석을 더 어렵게 한다는 주장도 나온다. 특정 후보와 자주 언급되는 단어가 긍정적인지 부정적인지를 살펴보는 기본적인 분석조차 쉽지 않다는 얘기다. AI 기반의 검색 서비스를 제공하는 한 스타트업 개발자는 “A당의 B 후보에 대해 ‘웃기고 있다’든가 ‘잘들 한다’는 표현이 많이 나왔을 때 기계가 이런 반어적 뉘앙스까지 구분하긴 어려운 실정”이라며 “한국어 분석 기술이 더 발달해야 정확한 선거 예측이 가능할 것”이라고 말했다. <관련기사> 중앙일보
결론
한국의 경우에는 언어의 특수성으로 상대적으로 예측하는 부분이 검색량기준의 텍스트마이닝의 결과를 보여주는 과정이었다고 2018년도 기준으로 분석하였고, 5년이 지난 지금은 어느정도 까지 발전되었는지? 구체적으로 탐구해보는것도 학생의 탐구력을 보여줄 수 있는 부분입니다.
오늘은 정치외교학과 사회학과 문과 학생들의 확률과 통계에서의 생기부 주제찾기를 탐구해봤습니다.